 Home
Home
|
 Documentation
Documentation
|
 General Notes
General Notes
|
|
PyGETS Guide
|
|
PyGEMZ Guide
|
 PyGERS Guide
PyGERS Guide
|
|
Credits
|
|
Project Page
|
|
Downloads
|
|
|
|
|
|
|
|
|
|
|
|
Home
|
|
Documentation
|
|
General Notes
|
|
PyGETS Guide
|
|
PyGEMZ Guide
|
|
PyGERS Guide
|
|
Credits
|
|
Project Page
|
|
Downloads
|
|
|
|
|
|
|
|
|
|
|
 |
Python Gutenberg E-text Project |
There are now thousands of e-text titles provided by Project Gutenberg, with some available in multiple formats. The Project Gutenberg web site includes some web-based tools for locating e-texts by title or author searches. While these tools are good for locating e-texts about which something is already known, they are not always the best method for discovering works with authors or titles that are unfamiliar to the reader. There exists a need for a tool which provides an experience similar to browsing through books on a bookshelf, with the added functionality of computer assistance to help focus and tailor browsing for each individual.
PyGETS is a tool for letting users browse through the contents of the Project Gutenberg collection, and then easily download those e-texts which appear interesting. Browsing through available e-texts is enhanced by user-directed filtering and sorting functions.
Information about available e-texts is initially downloaded from the Project Gutenberg web site by querying and extracting information from thousands of individual web pages. Each web page contains information on a single title provided by Project Gutenberg. Once all the information is collected, it is written to a local contents file for use in all subsequent browsing operations. A second history file will simultaneously be created to record which pages have been scanned for information.
The default name for the contents file used by PyGETS is "gutenberg.xml", while the default name for the associated history file is "gutenberg.hst".
PyGETS provides functions for acquiring and maintaining information in contents files. These functions are invoked with File menu commands.
An existing contents file can be opened by invoking the File->Open... menu command, resulting in a file locator dialog box for specifying the location of the file. Specifying a content file location and clicking on the OK button will load the content information and show it in the main contents display area under four named categories: Release, Version, Type, and Author
A new contents file can be created by invoking the File->Acquire... menu command. After the command is issued, a file locator dialog box will pop up for specifying the name and location of the files that are to contain the results of acquisition. Specifying an output location and clicking on the OK button will initiate a sequence of web queries.
Note that each full acquisition involves querying thousands of web pages, and may take several hours to complete if Project Gutenberg servers are heavily loaded.
Once started, a dialog window titled "Acquisition" will appear to indicate the progress of an acquisition command. This dialog will appear similar to the figure shown below.
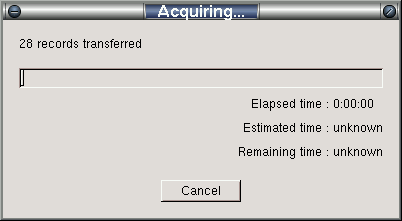
Clicking the Cancel button on the Acquisition dialog will bring up a confirmation dialog. If confirmed, cancelling acquisition will result in already acquired data being written to the specified output files before closing the dialog.
When an existing or partial contents file exists, time can be saved over acquiring completely new contents data by updating the list of known contents only with data from web pages that have not been visited before. PyGETS tracks which pages have already been scanned through a history file associated with each contents file.
After a contents file has been opened, its information can be updated by invoking the File->Update menu command. This command initiates a query to the Project Gutenberg web site for information about e-text titles that have not been previously included.
Once started, a dialog window titled "Updating" will appear to indicate the progress of an update command. This dialog will appear similar to the figure shown below.
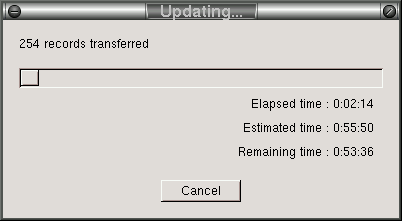
Clicking the Cancel button on the Updating dialog will bring up a confirmation dialog. If confirmed, cancelling updating will result in already acquired data being added to the main content display list after closing the dialog.
Note that newly updated contents data is not automatically written to a file, and will need to be explicitly saved (see below) for use in future sessions.
When contents data has been updated with new information, the user will often wish to save the results into either an existing contents file, or possibly a new one. Invoking the File->Save... menu command results in a file dialog which lets the user select a location for the updated contents. After selecting a location, clicking on the OK button of the dialog writes out results to the designated file, while clicking on the Cancel button aborts the entire save operation.
The PyGERS e-text reading program uses an index file which contains information about authors and titles that has been appropriately formatted for use on a title page, indexed by the Project Gutenberg e-text number assigned to each title. The default name for the index file used by PyGERS is "gutenberg.idx".
This index file can be created from PyGETS contents information by invoking the File->Index... menu command. A file locator dialog box for specifying the intended location of the index file will appear upon issuing the command. Specifying an index file location and clicking on the OK button will write out current contents information to the index file.
|
Last modified: Mon Aug 11 01:19:06 PST 2003 |
Copyright © Gary Shao, 2003. All rights reserved. |